Parametric methods that normalize data but require careful handling to avoid numerical instability.
Numerical
Transform
Python
Author
Xuefeng Xu
Published
April 14, 2025
Power transforms are parametric methods that convert data into a Gaussian-like distribution. Two widely used transformations in this category are the Box-Cox (Box and Cox 1964) and Yeo-Johnson (Yeo and Johnson 2000) methods, both of which rely on a single parameter \lambda.
1 Two Transformations
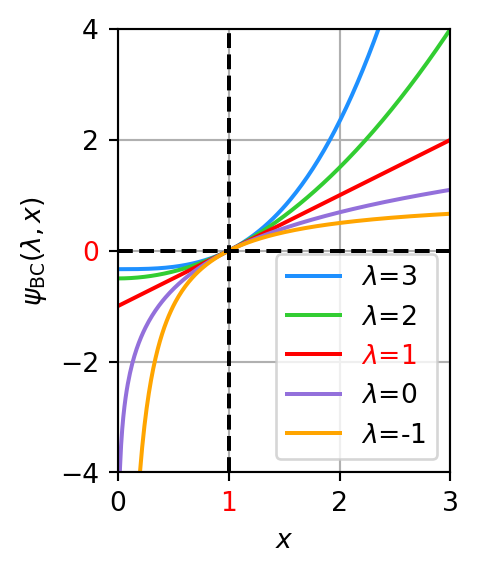
The Box-Cox transformation requires strictly positive data (x > 0) and is defined as:
Here, \sigma^2_\psi represents the variance of the transformed data, \text{Var}[\psi(\lambda,x)]. These log-likelihood functions are concave (Kouider and Chen 1995; Marchand et al. 2022), which guarantees a unique maximum. Brent’s method (Brent 2013) is commonly employed for optimization.
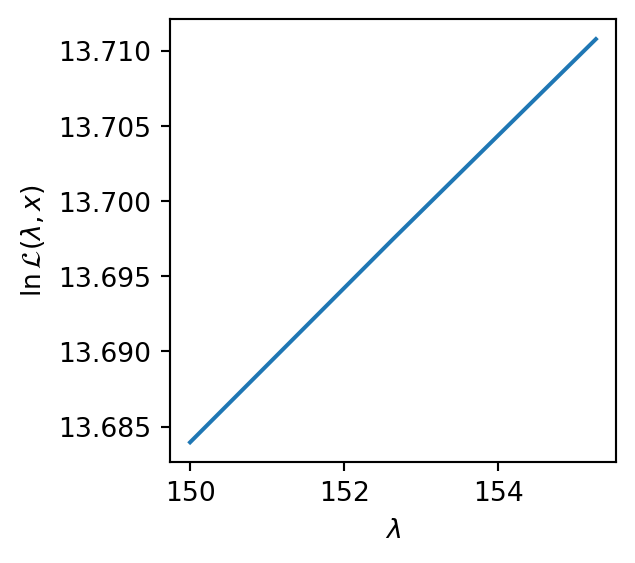
Because both transformations involve exponentiation, they are susceptible to numerical overflow. This problem has been observed by (Marchand et al. 2022) and discussed in Scikit-learn’s GitHub Issue. Below is an example illustrating the problem using a naive implementation of Equation 3:
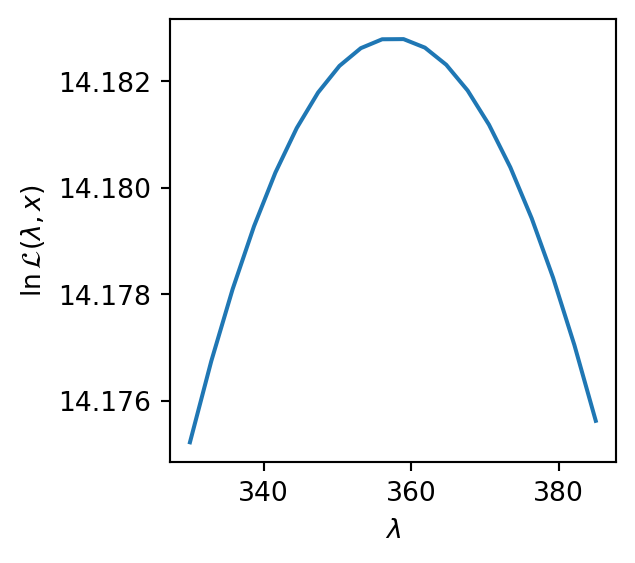
Unfortunately, due to overflow (np.inf values), the log-likelihood curve cannot be visualized in the specified range, suggesting the returned \lambda is not optimal.
3 Existing Solutions
The MASS package in R (Venables and Ripley 2002) proposes a simple yet effective trick: divide the data by its mean. This rescales the data and avoids numerical instability without affecting the optimization outcome.
x_dm = x / np.mean(x)print(max_llf(x_dm, llf=boxcox_llf_naive))
\begin{align*}
&\ln\mathcal{L}_{\text{BC}}(\lambda, x/c) \\
=&(\lambda-1) \sum_i^n \ln(x_i/c) - \frac{n}{2}\ln\text{Var}[\psi_{\text{BC}}(\lambda,x/c)] \\
=&\ln\mathcal{L}_{\text{BC}}(\lambda, x) - n(\lambda-1)\ln c + n\lambda\ln c \\
=&\ln\mathcal{L}_{\text{BC}}(\lambda, x) + n\ln c \\
\end{align*}
\tag{7}
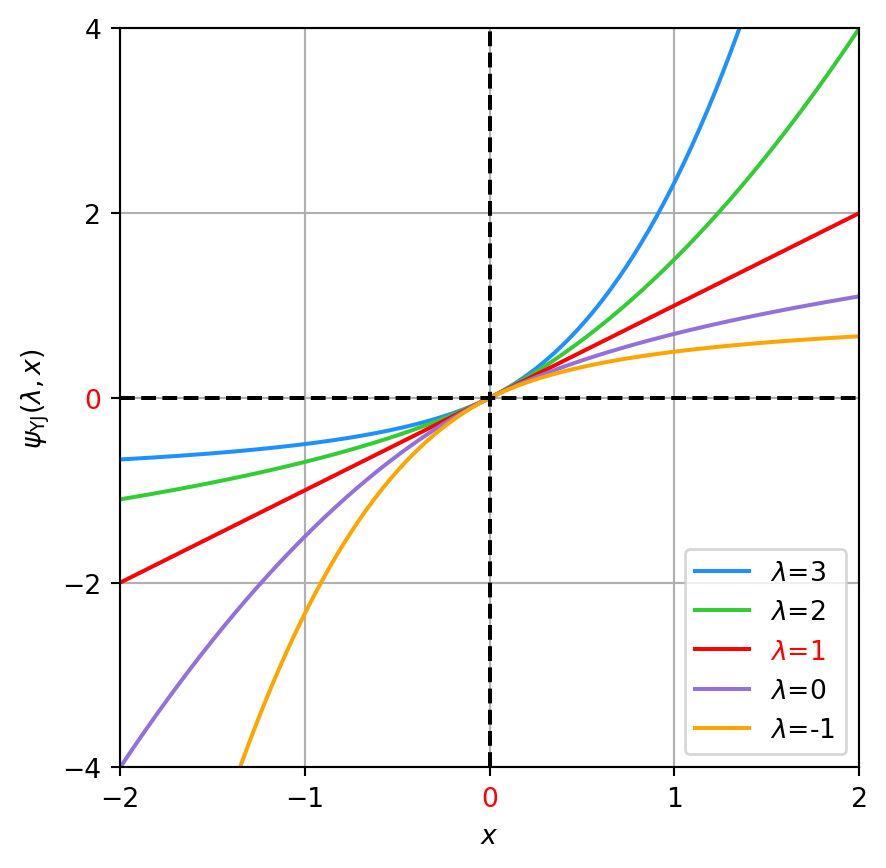
The additive constant n\ln c does not affect the maximizer of \lambda. However, this trick does not apply to Yeo-Johnson, where scaling alters the optimal parameter (see Equation 4).
4 Log-Domain Computation
To address numerical instability for both transformations, log-domain computation (Haberland 2023) is effective. It uses the Log-Sum-Exp trick to compute statistics in log domain:
from scipy.special import logsumexpdef log_mean(logx):# compute log of mean of x from log(x)return logsumexp(logx) - np.log(len(logx))def log_var(logx):# compute log of variance of x from log(x) logmean = log_mean(logx) pij = np.full_like(logx, np.pi *1j, dtype=np.complex128) logxmu = logsumexp([logx, logmean + pij], axis=0)return np.real(logsumexp(2* logxmu)) - np.log(len(logx))
This allows direct computation of \ln\sigma^2_\psi from \ln x. Plugging in Equation 5, we can compute the log-likelihood in the log-domain.
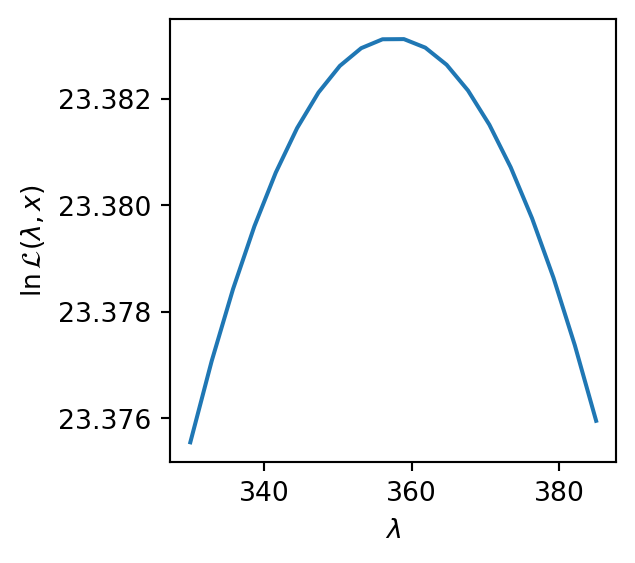
The constrained optimization approach can also be extended to Yeo-Johnson, ensures overflow-free transformations even for extreme values.
Code
def yeojohnson_inv_lmbda(x, y):if x >=0: num = lambertw(-((x +1) ** (-1/ y) * np.log1p(x)) / y, k=-1)return-1/ y + np.real(-num / np.log1p(x))else: num = lambertw(((1- x) ** (1/ y) * np.log1p(-x)) / y, k=-1)return-1/ y +2+ np.real(num / np.log1p(-x))def yeojohnson_constranined_lmax(lmax, x, ymax):# x > 0, yeojohnson(x) > 0; x < 0, yeojohnson(x) < 0 xmin, xmax =min(x), max(x)if xmin >=0: x_treme = xmaxelif xmax <=0: x_treme = xminelse: # xmin < 0 < xmaxwith np.errstate(over="ignore"): indicator = yeojohnson(xmax, lmax) >abs(yeojohnson(xmin, lmax)) x_treme = xmax if indicator else xminwith np.errstate(over="ignore"):ifabs(yeojohnson(x_treme, lmax)) > ymax: lmax = yeojohnson_inv_lmbda(x_treme, ymax * np.sign(x_treme))return lmax
References
Box, G. E. P., and D. R. Cox. 1964. “An Analysis of Transformations.”Journal of the Royal Statistical Society: Series B (Methodological) 26 (2): 211–43. https://doi.org/10.1111/j.2517-6161.1964.tb00553.x.
Brent, Richard P. 2013. Algorithms for Minimization Without Derivatives. Dover Books on Mathematics. Dover Publications, Incorporated.
Kouider, Elies, and Hanfeng Chen. 1995. “Concavity of Box-Cox Log-Likelihood Function.”Statistics & Probability Letters 25 (2): 171–75. https://doi.org/10.1016/0167-7152(94)00219-X.
Marchand, Tanguy, Boris Muzellec, Constance Béguier, Jean Ogier du Terrail, and Mathieu Andreux. 2022. “SecureFedYJ: A Safe Feature Gaussianization Protocol for Federated Learning.”Advances in Neural Information Processing Systems 35: 36585–98. https://doi.org/10.48550/arXiv.2210.01639.
Yeo, In‐Kwon, and Richard A. Johnson. 2000. “A New Family of Power Transformations to Improve Normality or Symmetry.”Biometrika 87 (4): 954–59. https://doi.org/10.1093/biomet/87.4.954.