Graphical tools for evaluating classification models, highlighting trade-offs in model performance.
Machine Learning
Metric
Python
Author
Xuefeng Xu
Published
July 31, 2025
Receiver Operating Characteristic (ROC) and Precision–Recall (PR) curves are tools for evaluating classification models. They visualize trade-offs between True Positive Rate (TPR) and False Positive Rate (FPR) (ROC) or Precision and Recall (PR), offering deeper insights than single scalar metrics.
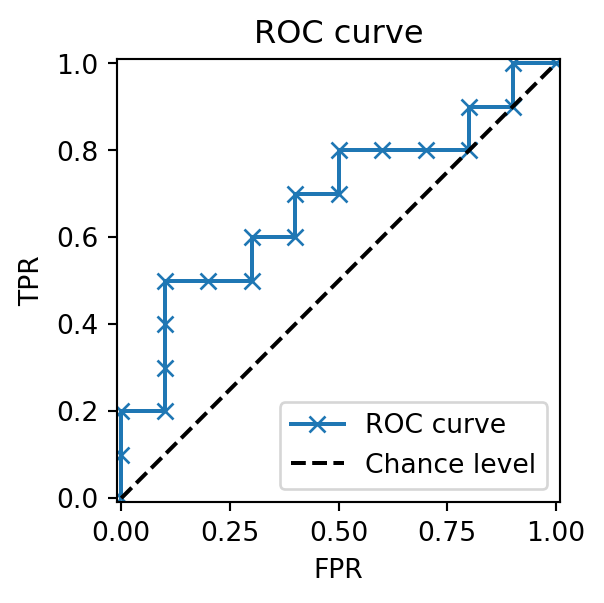
1 ROC Curve
For binary classification, with Positive (P) and Negative (N) classes, predictions are based on model scores thresholded to produce labels. Performance is summarized using a confusion matrix (Table 1), counting True Positives (TP), False Positives (FP), True Negatives (TN), and False Negatives (FN).
A simple algorithm constructs the ROC curve: (i) Sort predictions in descending score order. (ii) Sweep thresholds across scores, updating TP and FP counts (Fawcett 2006).
The ROC curve is always monotonically non-decreasing, starting at (0, 0) for the highest threshold and ending at (1, 1) for the lowest threshold. Points are connected using linear interpolation. A random classifier lies along y=x, while curves closer to the top-left indicate better performance.
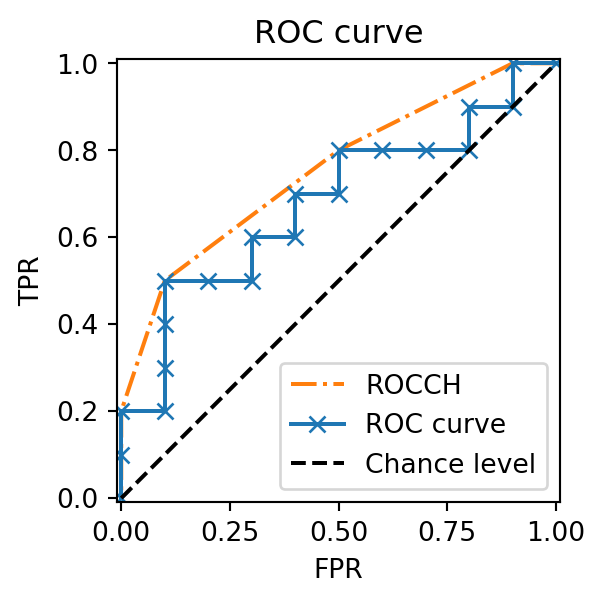
The ROC Convex Hull (ROCCH) highlights potentially optimal performance of a classifier (or a set of classifiers) by connecting upper boundary points (Provost and Fawcett 2001). It can be computed via algorithms like the Monotone chain algorithm.
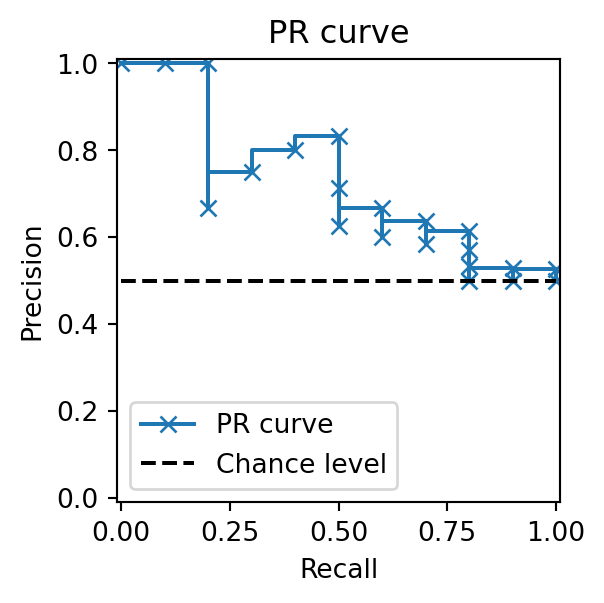
PR curves start at (0, 1) and end at (1, \frac{\text{P}}{\text{P}+\text{N}}), where the endpoint reflects the proportion of positive samples. Because Precision depends on both TP and FP, the PR curve is non-monotonic and can decrease as Recall increases. Moreover, it is highly influenced by class imbalance (Williams 2021). For a random classifier, the PR curve is a horizontal line at y = \frac{\text{P}}{\text{P}+\text{N}}, whereas curves closer to the top-right indicate stronger performance.
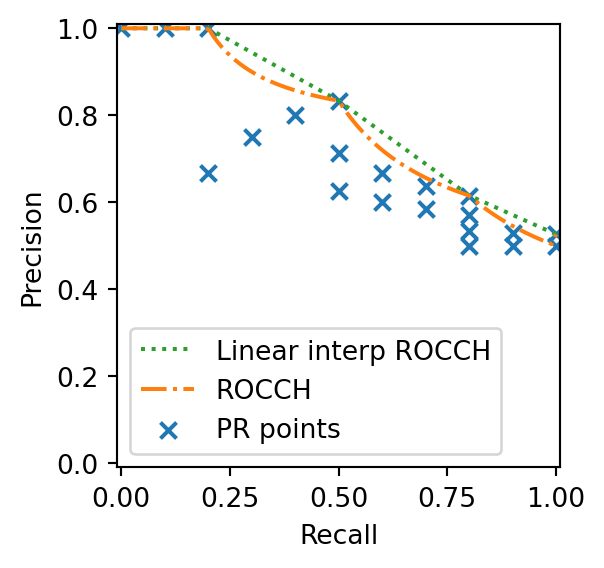
Although ROC and PR curves are mathematically related, linear interpolation is incorrect for PR curves, as it yields overly optimistic estimates of performance (Davis and Goadrich 2006). Precision does not necessarily vary linearly with Recall, so naive interpolation misrepresents true model behavior.
To illustrate this, we convert the ROC Convex Hull (ROCCH) into PR space, treating it as the potential optimal PR curve. Using Equation 3, we express Precision in terms of TPR and FPR:
The converted ROCCH dominates the PR space but is clearly non-linear, lying beneath its own linear interpolation (dotted line). This confirms that PR curves cannot be linearly interpolated. Scikit-learn’s PrecisionRecallDisplay instead uses step-wise interpolation, consistent with average_precision_score. This ensures that the area under the PR curve equals the average precision.
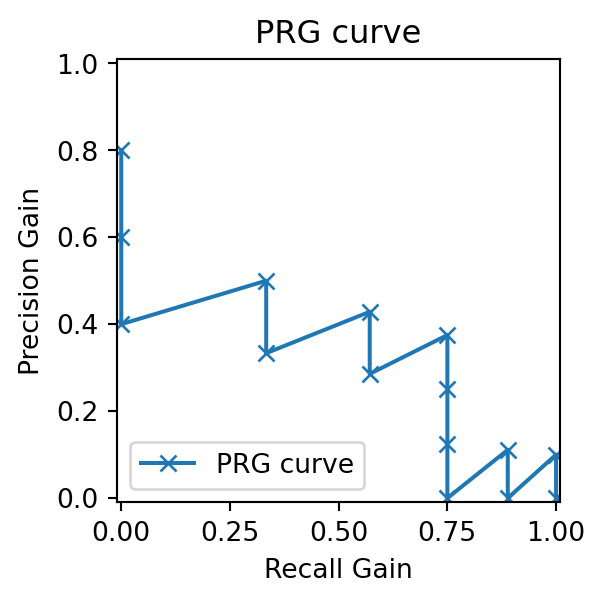
ROC curves benefit from linear interpolation and universal baselines, whereas PR curves lack these properties. To address this, Flach and Kull (2015) proposed the Precision–Recall-Gain (PRG) curve, which transforms Precision and Recall into Gains and plots these Precision Gain and Recall Gain within the unit square:
where \pi=\frac{\text{P}}{\text{P}+\text{N}} is the positive class fraction. Notably, Gains can be negative, and such points are typically omitted from the PRG curve.
Davis, Jesse, and Mark Goadrich. 2006. “The Relationship Between Precision-Recall and ROC Curves.”Proceedings of the 23rd International Conference on Machine Learning (New York, NY, USA), ICML ’06, 233–40. https://doi.org/10.1145/1143844.1143874.
Flach, Peter, and Meelis Kull. 2015. “Precision-Recall-Gain Curves: PR Analysis Done Right.”Advances in Neural Information Processing Systems 28. http://papers.nips.cc/paper/by-source-2015-535.
Provost, Foster J., and Tom Fawcett. 2001. “Robust Classification for Imprecise Environments.”Machine Learning 42 (3): 203–31. https://doi.org/10.1023/A:1007601015854.
Williams, Christopher K. I. 2021. “The Effect of Class Imbalance on Precision-Recall Curves.”Neural Computation 33 (4): 853–57. https://doi.org/10.1162/neco_a_01362.
Citation
BibTeX citation:
@misc{roc-pr-curve,
author = {Xu, Xuefeng},
title = {ROC, {PR,} and {PRG} {Curves}},
date = {2025-07-31},
url = {https://xuefeng-xu.github.io/blog/roc-pr-curve.html},
langid = {en}
}